iptables
本文由 Codex 辅助生成,内容整理自 B 站「米拉一老王」的 iptables 学习资料。
简介
iptables 常被直接叫做 Linux 防火墙,但更准确一点说,它是一个用户态命令行工具,用来给 Linux 内核里的 netfilter 写规则。
netfilter 才是真正工作在内核里的包处理框架。数据包进入协议栈后,会在几个固定位置经过 netfilter 的 hook 点;iptables 把规则挂到这些 hook 对应的链上,内核经过链时按顺序匹配规则,匹配到了就执行对应动作。
写 iptables 规则时,可以先把需求翻译成下面这几个问题:
1 | 需求是什么 -> 要做什么动作 -> 用哪张表 -> 写到哪条链 -> 补上匹配条件 |
例如:
- 需求:禁止别人访问本机 80 端口
- 动作:丢弃数据包
- 表:filter 表
- 链:INPUT 链
- 规则:匹配 TCP 目标端口 80,然后 DROP
先建立一个简单模型
刚开始学 iptables 时,不要先背命令,先记住一句话:
1 | 数据包经过内核时,netfilter 在几个固定位置设置了检查点,iptables 用来给这些检查点写规则。 |
这些检查点就是常说的“链”。每条规则本质上都在回答三个问题:
- 在哪里检查?也就是选哪条链。
- 检查什么包?也就是写匹配条件。
- 命中后怎么办?也就是选动作。
数据包会经过哪些链
入站和出站流量
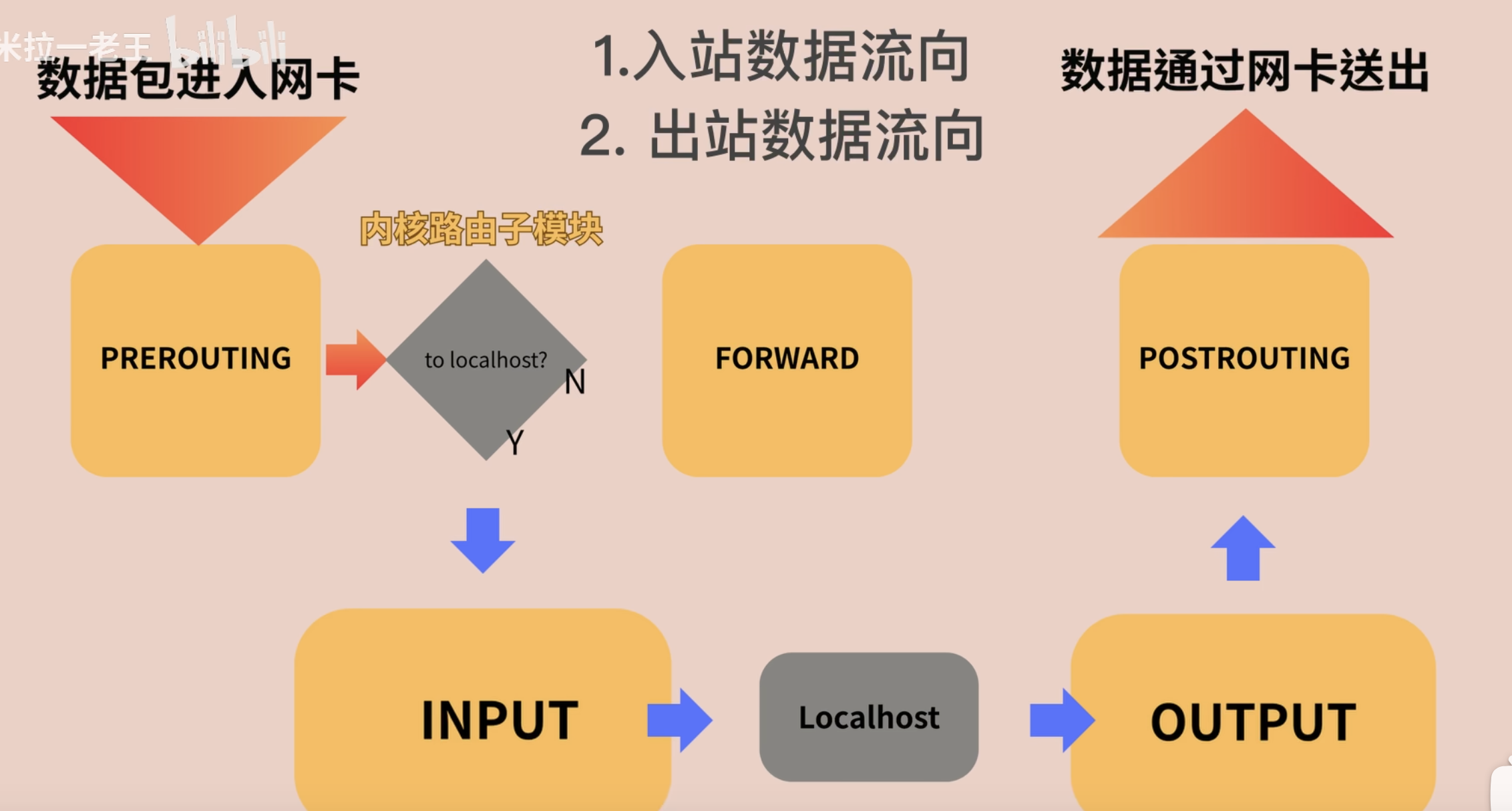
这张图画了两种最常见的流量。
第一种是别人访问本机,比如访问这台机器的 80 端口:
1 | 数据包进入网卡 -> PREROUTING -> 路由判断目标是本机 -> INPUT -> 本机进程 |
第二种是本机主动访问外部服务,比如执行 curl https://example.com:
1 | 本机进程 -> OUTPUT -> POSTROUTING -> 数据包通过网卡发出 |
这里图里的 localhost 可以先理解为“本机上的进程或服务”,不必纠结它是不是 127.0.0.1。
先记结论:
- 别人访问本机:重点看
INPUT - 本机主动访问别人:重点看
OUTPUT
转发流量
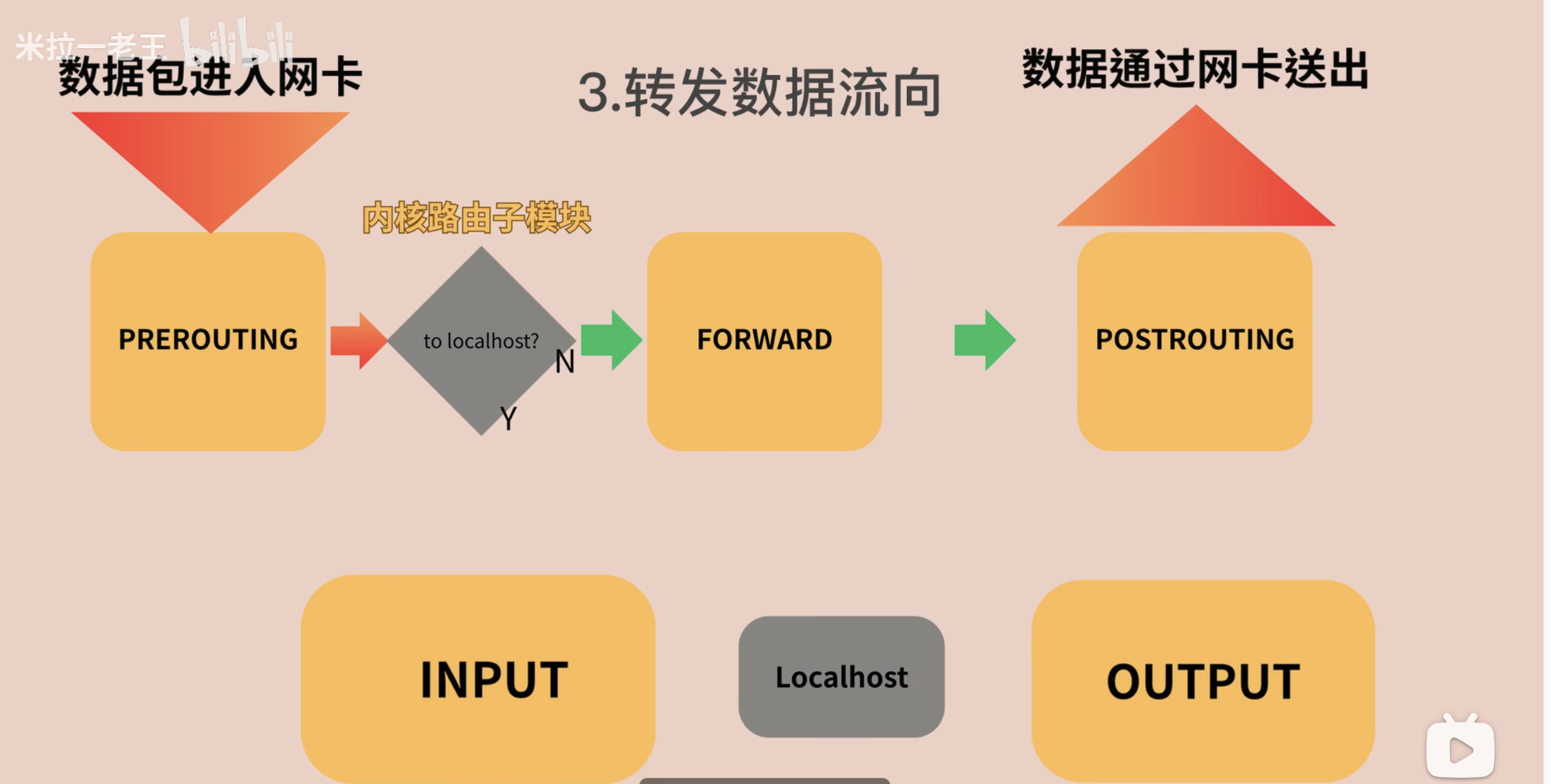
这张图画的是 Linux 作为路由器或网关时的场景。
如果数据包进入本机后,路由判断发现目标不是本机,而是需要从另一块网卡转发出去,就会走 FORWARD 链:
1 | 数据包进入网卡 -> PREROUTING -> 路由判断目标不是本机 -> FORWARD -> POSTROUTING -> 网卡发出 |
FORWARD 链只处理经过本机转发的流量,不处理访问本机服务的流量。
常见链可以这样记:
| 链 | 初学者理解 | 常见场景 |
|---|---|---|
| PREROUTING | 数据包刚进来,还没决定去哪 | DNAT、提前标记 |
| INPUT | 数据包要进入本机 | 控制别人访问本机 |
| FORWARD | 数据包经过本机转发 | Linux 当路由器或网关 |
| OUTPUT | 本机发出去的数据包 | 控制本机访问外部 |
| POSTROUTING | 数据包准备从网卡出去 | SNAT、MASQUERADE |
表:规则按用途分类

链解决的是“数据包走到哪里”,表解决的是“我要对数据包做哪类事情”。
| 表 | 图中含义 | 我的理解 |
|---|---|---|
| raw | 在连接跟踪处理前进行特定处理,优先级最高 | 很早期介入,常用于跳过连接跟踪 |
| mangle | 对数据包进行拆包、修改、再封包的处理 | 修改包的属性,比如 mark、TTL、TOS |
| nat | 所有地址转换相关的操作 | 做 DNAT、SNAT、MASQUERADE |
| filter | 负责过滤,比如防火墙功能 | 最常用,用来 ACCEPT、DROP、REJECT |
初学阶段先重点记两张表:
filter:控制包能不能通过,也就是最常见的防火墙规则。nat:修改源地址或目标地址,比如端口转发、共享上网。
raw 和 mangle 可以先知道名字,等遇到连接跟踪、打 mark、改 TTL 这类需求时再深入。
表和链的关系
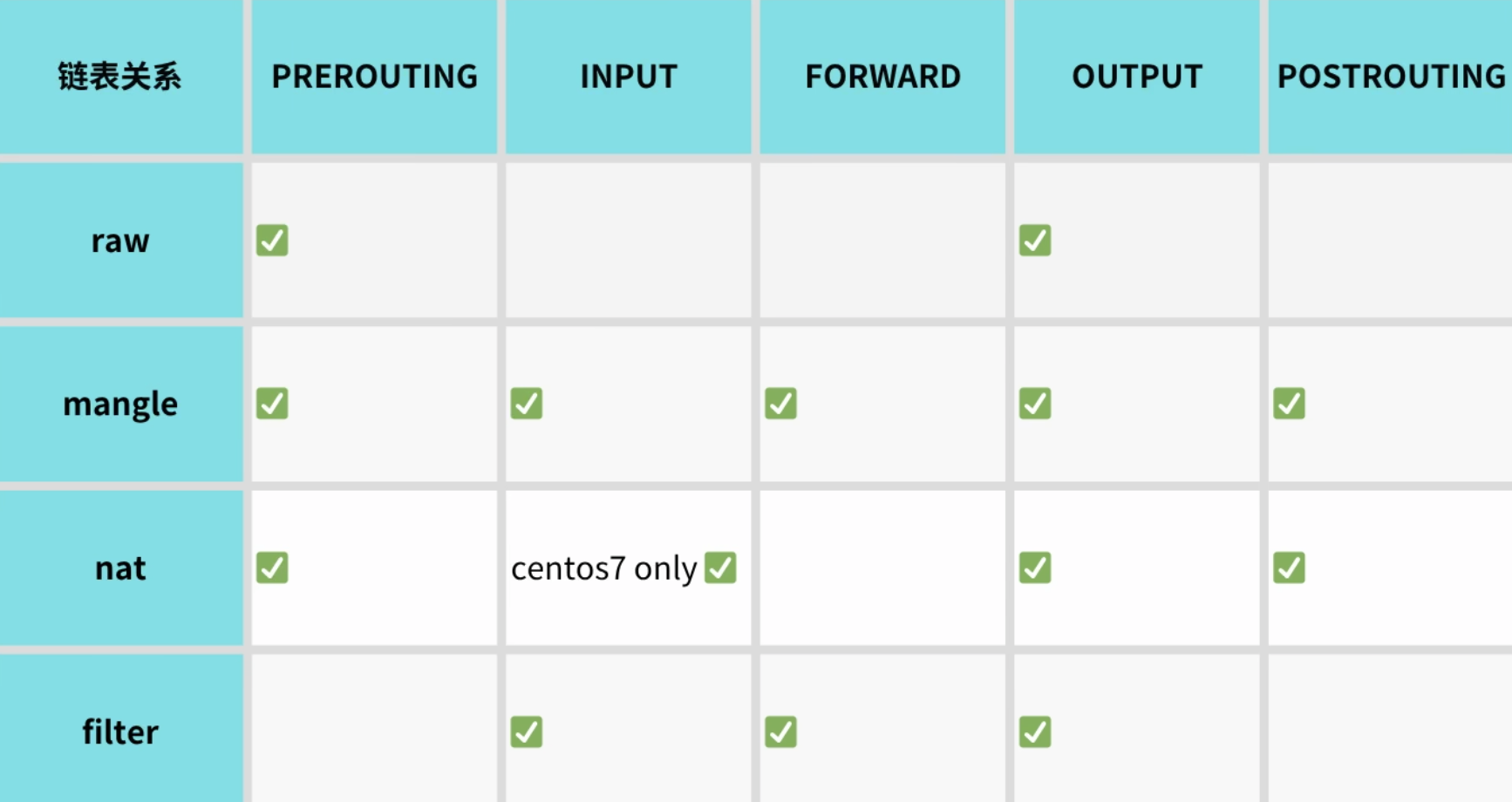
不是每张表都能写到每条链上。比如 filter 表没有 PREROUTING 和 POSTROUTING,因为过滤本机流量通常发生在 INPUT、OUTPUT、FORWARD 这些位置。
| 表 / 链 | PREROUTING | INPUT | FORWARD | OUTPUT | POSTROUTING |
|---|---|---|---|---|---|
| raw | 支持 | 不支持 | 不支持 | 支持 | 不支持 |
| mangle | 支持 | 支持 | 支持 | 支持 | 支持 |
| nat | 支持 | 部分系统支持 | 不支持 | 支持 | 支持 |
| filter | 不支持 | 支持 | 支持 | 支持 | 不支持 |
初学时不用把整张表硬背下来,先记这几个高频组合:
- 过滤访问本机的流量:
filter表 +INPUT链 - 过滤本机发出的流量:
filter表 +OUTPUT链 - 过滤转发流量:
filter表 +FORWARD链 - 修改目标地址:
nat表 +PREROUTING链 - 修改源地址:
nat表 +POSTROUTING链
比如“禁止别人访问本机 80 端口”:
- 访问本机,所以看
INPUT - 要过滤流量,所以用
filter
动作:匹配后怎么办

规则匹配成功后,需要告诉内核怎么处理这个包。这个动作写在 -j 后面,也叫 target。
| 动作 | 含义 | 常见用途 |
|---|---|---|
| ACCEPT | 接受数据包,允许通过 | 放行流量 |
| DROP | 丢弃数据包,不返回任何响应 | 静默拒绝访问 |
| REJECT | 拒绝数据包,并返回错误信息 | 明确告诉对方被拒绝 |
| LOG | 记录数据包信息到日志 | 排障、观察命中情况 |
| DNAT | 目标地址转换 | 端口转发、负载入口 |
| SNAT | 源地址转换 | 固定出口地址转换 |
| MASQUERADE | 动态源地址转换 | 出口 IP 不固定时做 NAT |
初学者最常用的是前三个:
ACCEPT:放行DROP:丢掉,而且不告诉对方REJECT:拒绝,并告诉对方
从需求推导规则
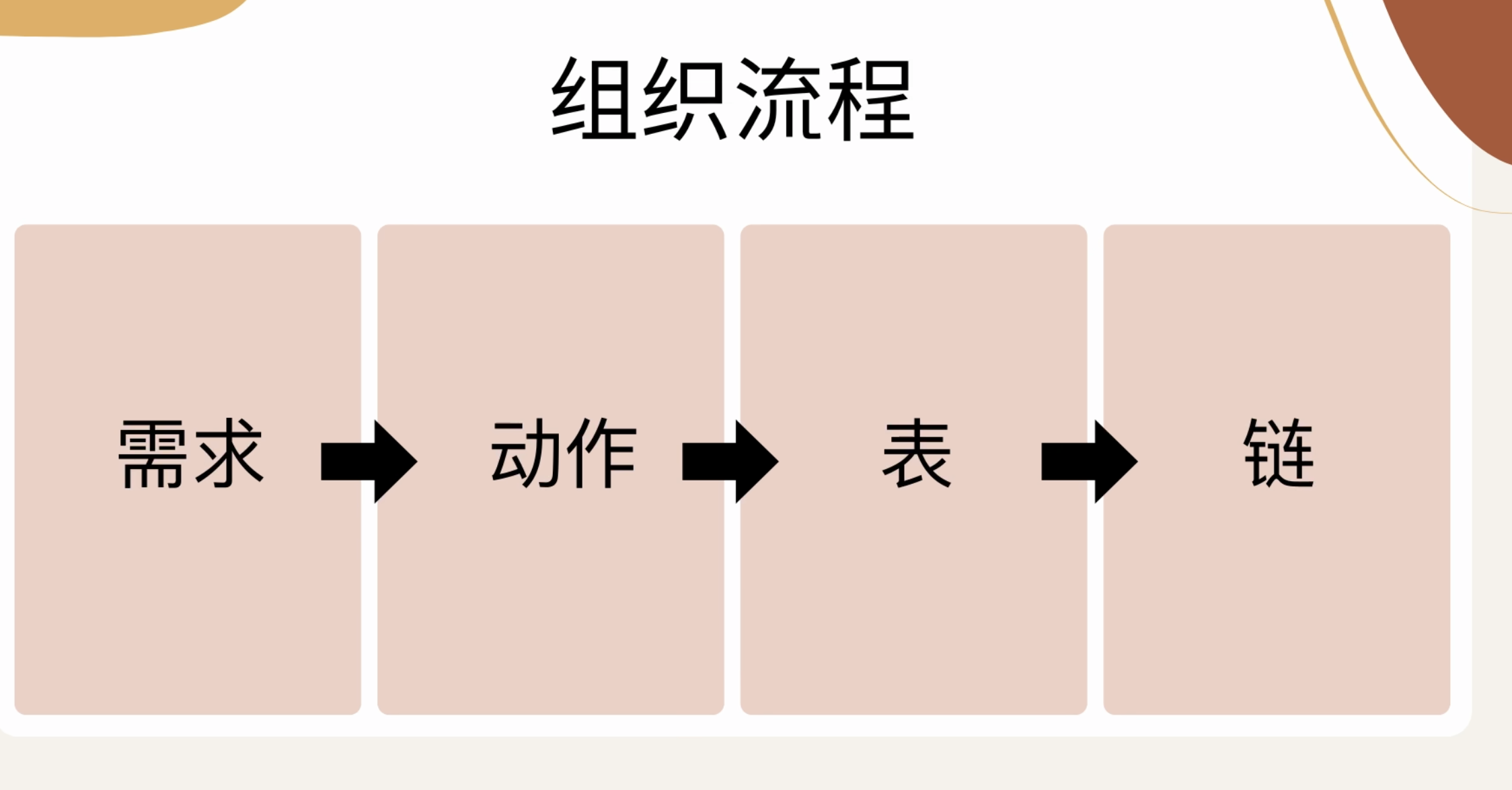
这张图是写规则的核心方法。不要先背命令,先按这个顺序想:
1 | 需求 -> 动作 -> 表 -> 链 |
例如“丢掉访问本机 TCP 80 端口的数据包”:
- 需求:禁止访问本机 80 端口
- 动作:丢弃数据包,也就是
DROP - 表:过滤流量,用
filter - 链:访问本机,用
INPUT
再补上匹配条件:
- 协议:TCP,写
-p tcp - 目标端口:80,写
--dport 80
最后得到完整规则:
1 | iptables -t filter -A INPUT -p tcp --dport 80 -j DROP |
核心概念
到这里,几个核心概念可以这样收束:
| 概念 | 解决的问题 | 例子 |
|---|---|---|
| 表 table | 我要做哪类事情 | filter、nat |
| 链 chain | 数据包走到了哪个位置 | INPUT、OUTPUT、FORWARD |
| 规则 rule | 具体的一条处理逻辑 | 匹配 TCP 80 端口然后 DROP |
| 匹配 match | 找出我要处理的数据包 | -p tcp --dport 80 |
| 动作 target | 命中后怎么处理 | ACCEPT、DROP |
iptables 会从链的第一条规则开始往下匹配。匹配到规则后就执行对应动作;如果一直没有匹配到,就执行这条链的默认策略。
基本语法
iptables 命令大体长这样:
1 | iptables [-t 表名] 操作 链名 匹配条件 -j 动作 |
常用操作:
| 操作 | 含义 |
|---|---|
-A |
append,追加到链末尾 |
-I |
insert,插入到指定位置,默认插到第一条 |
-D |
delete,删除规则 |
-L |
list,查看规则 |
-P |
policy,设置内置链默认策略 |
-F |
flush,清空规则 |
参数是区分大小写的,这点很容易踩坑:
-p表示协议,比如-p tcp-P表示默认策略,比如-P INPUT DROP-i表示入接口-I表示插入规则INPUT、OUTPUT、ACCEPT、DROP这些链名和动作通常大写filter、nat、mangle、raw这些表名通常小写
使用场景
丢掉访问本机 TCP 80 端口的数据包
1 | iptables -t filter -A INPUT -p tcp --dport 80 -j DROP |
因为默认就是 filter 表,也可以省略 -t filter:
1 | iptables -A INPUT -p tcp --dport 80 -j DROP |
这条规则的意思是:
-A INPUT:追加到INPUT链,处理访问本机的数据包-p tcp:匹配 TCP 协议--dport 80:匹配目标端口 80-j DROP:匹配后直接丢弃
默认拒绝全部入站,只打开 UDP 53
注意:如果是在远程服务器上操作,先确认 SSH 端口已经放行,否则很容易把自己锁在门外。
先放行已有连接和本机回环流量:
1 | iptables -A INPUT -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT |
再放行 UDP 53:
1 | iptables -A INPUT -p udp --dport 53 -j ACCEPT |
最后把 INPUT 链默认策略改成 DROP:
1 | iptables -P INPUT DROP |
为什么要加 ESTABLISHED,RELATED?
因为默认丢弃入站包后,本机主动访问外部服务时,请求可以从 OUTPUT 出去,但对方回来的响应包会进入 INPUT。如果不放行已有连接的回包,本机很多主动出站请求也会表现得像失败。
旧写法也常见:
1 | iptables -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT |
现在更推荐使用 conntrack:
1 | iptables -A INPUT -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT |
查看 filter 表 INPUT 链规则
1 | iptables -t filter -L INPUT -n -v --line-numbers |
参数说明:
-L INPUT:查看INPUT链-n:不要反查域名和服务名,显示更快更直观-v:显示命中次数、字节数、接口等详细信息--line-numbers:显示规则编号,方便插入和删除
在指定位置前插入新规则
把允许 UDP 54 的规则插入到 INPUT 链第 4 条之前:
1 | iptables -t filter -I INPUT 4 -p udp --dport 54 -j ACCEPT |
这里要用 -I,不是 -A。-A 只能追加到链末尾。
删除指定规则
删除 filter 表 INPUT 链的第 8 条规则:
1 | iptables -t filter -D INPUT 8 |
删除前建议先查看编号:
1 | iptables -t filter -L INPUT -n -v --line-numbers |
查看完整规则
iptables -L 更适合人工查看,iptables-save 更适合备份和排障:
1 | iptables-save |
它会按可恢复的格式输出当前所有表和规则。
小结
学习 iptables 可以先抓住四个问题:
- 我要处理什么流量?入站、本机出站,还是转发?
- 这个流量会经过哪条链?
INPUT、OUTPUT、FORWARD、PREROUTING还是POSTROUTING? - 我要做什么动作?过滤就用
filter,地址转换就用nat。 - 规则顺序对不对?iptables 从上往下匹配,默认策略优先级最低。
记住这条主线后,再看各种参数就不会乱:
1 | 先判断数据包流向 -> 再选链 -> 再选表 -> 最后写匹配和动作 |